We build the platform that helps enterprise teams win in generative search. If our own site couldn't show up in AI-generated answers, that'd be a credibility problem.
So we treated Gradial the way we treat any customer. We ran our own GEO report, identified the gaps, and used those insights to inform a site redesign that had been in motion.
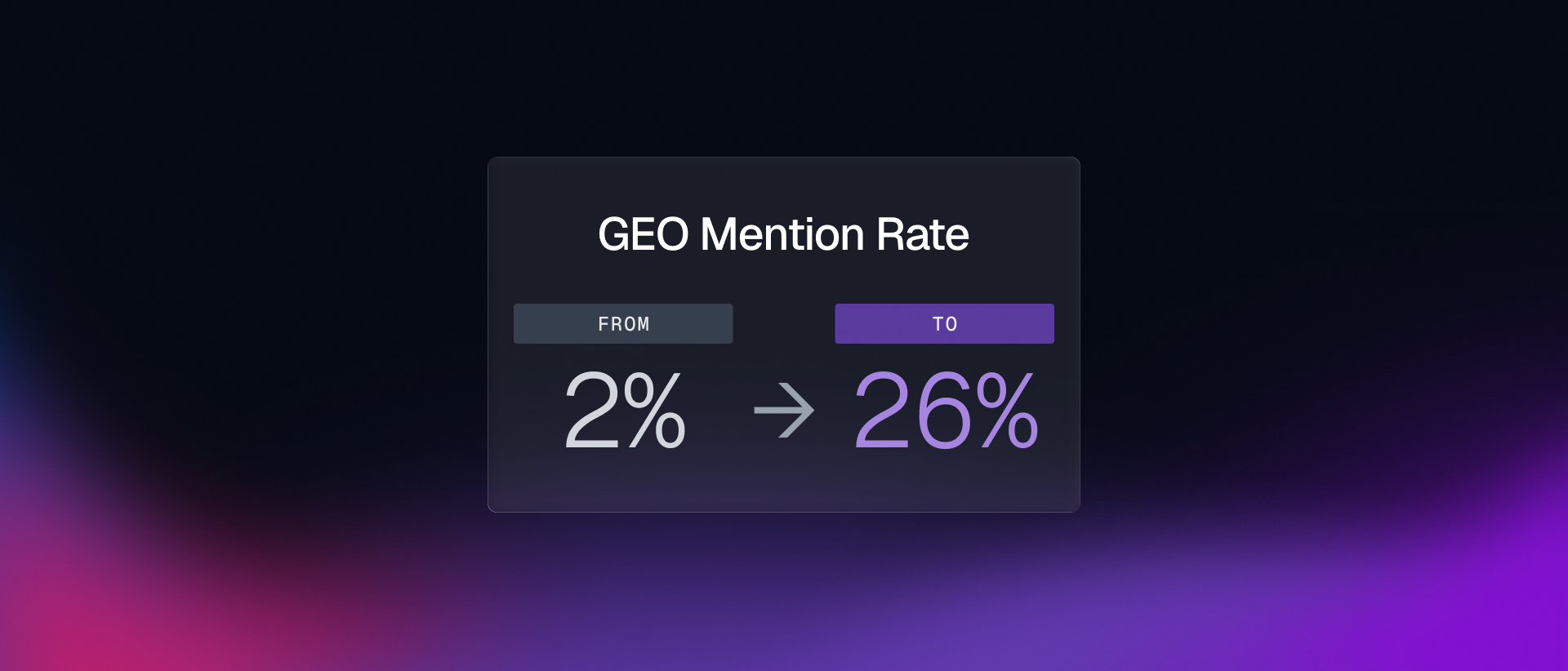
What Actually Moved the Number
The honest answer: the site redesign we shipped two weeks ago did the heavy lifting. The GEO agent is what told us where to aim.
Here's how those two things worked together.
The GEO agent surfaced the prompts that mattered. Not vanity keywords. The actual questions enterprise buyers type into AI search engines when they're evaluating marketing operations platforms, content automation tools, and CMS orchestration layers. Prompts like "best enterprise content ops platform," "marketing automation for large teams," and "how to automate content workflows at scale."
It audited what engines were saying. For each prompt, the agent tracked which brands were being cited, which pages were used as evidence, and where Gradial was missing from the conversation entirely. In most cases, we weren't being mentioned at all. Not because our product was irrelevant, but because our site didn't give engines what they needed to reference us confidently.
It flagged the structural gaps. The issues weren't about word count or publishing cadence. They were about how our pages were built. Thin comparison content. Product positioning scattered across too many places without a single authoritative source. Components that buried definitive claims inside marketing copy. No clear structured signals for LLMs to extract.
Our design and content teams used those insights to rebuild the site. This is the part that mattered. The redesign wasn't just a visual refresh. It was a structural rebuild informed by what the GEO agent told us LLMs needed. We rewrote core pages with the specificity AI engines reward. We restructured how product positioning lives on the site so there's a single authoritative source per topic. We built components that make definitive claims scannable and quotable. We added the kind of structured trust signals that LLMs pull into answers.
Then we measured again. Every week we re-ran the same prompts and tracked movement. The agent kept telling us which changes were working and where the next gaps were.